Clawd/Molbot/OpenClaw: Reflexiones y aprendizajes



¿Quieres mejorar los procesos de desarrollo, la eficiencia, la escalabilidad y seguridad en tu Cloud a la vez que ahorras costes?
Contacta con nuestro equipo de expertos en infraestructura Cloud y lleva tus aplicaciones al siguiente nivel.
Este post no pretende ser una guía de cómo usar Clawd sino más bien una muestra de cómo lo estamos implementando en Helmcode para poder tener un AI Agent que nos ayude con las tareas de nuestro día a día administrando infraestructura Cloud de múltiples startups.
Setup
En nuestra infraestructura hemos levantado un server Ubuntu y hemos instalado en él Clawd. A este le hemos enlazado Slack y solo está disponible en ciertos canales grupales.
Lo cierto es que su documentación es francamente buena y siguiendo los pasos de su script tardas 30 min en tener el agente listo para usar. Las guías que seguimos en su momento fueron:
- Instalación con los modelos de Anthropic.
- Configuración de Slack
Una vez el agente "cobró vida", dentro del server, instalamos varias CLI para poder interactuar con múltiples herramientas (kubectl, argocd, vault, etc). La instalación y configuración de las mismas se hizo de forma manual porque así controlamos y pre-configuramos todo antes de que Clawd interactúe con ellas.
En GitLab, hemos creado 3 repositorios para diferentes partes importantes de Clawd:
- memory: es "el cerebro" del agente. Va generando y actualizando ficheros en formato: YYYY-MM-DD.md para mantener contexto de las conversaciones que vas teniendo con él. Además, nosotros hemos movido el fichero MEMORY.md dentro de este directorio para tenerlo también en repositorio. Este fichero es la memoria "principal" del agente y tiene un orden de prioridad superior a los demas ficheros que se van generando.
- scripts: el agente va generando scripts para diferentes cosas que va necesitando o que le vamos pidiendo. Como, por ejemplo, pre-cargar una configuración para poder usar ciertas herramientas. Todo esto para que esté centralizado, le hemos indicado al agente que debe almacenar todos los scripts aquí para tener en repositorio este código.
- clients: este directorio contiene "skills" custom nuestras con lógica de negocio y para darle ejemplos al agente de cómo debe hacer ciertas cosas y cómo puede obtener la capacidad de interactuar con las diferentes infraestructuras que gestionamos. Este punto es crítico porque también le indicamos cómo interactuar con Vault para poder autenticarse en cada infraestructura de cliente.
El agente puede actualizar y subir cosas directamente a repositorio tanto en memory como en scripts. En clients para poder actualizar cualquier cosa, nos abre una PR, para que nosotros revisemos antes de hacer merge de sus cambios. Ya que tenemos que validar que estos cambios cumplen con nuestra lógica de negocio.

Pruebas
Lo más simple funcionaba sin problemas. Pedirle que vea la hora del sistema o consultar por el usuario con el que corre funcionaba pero esto no sorprendía. Cualquiera que haya trabajado o jugado un poco con agentes sabe que ejecutar comandos en la terminal hace tiempo que no es un misterio (salvo con AWS CLI que es horrible y hasta los agentes se atascan de vez en cuando 😂).
Lo interesante fue entrar en flujos un poco más complejos. Por ejemplo, estas son algunas de las pruebas que hemos conseguido hacer hasta el momento:
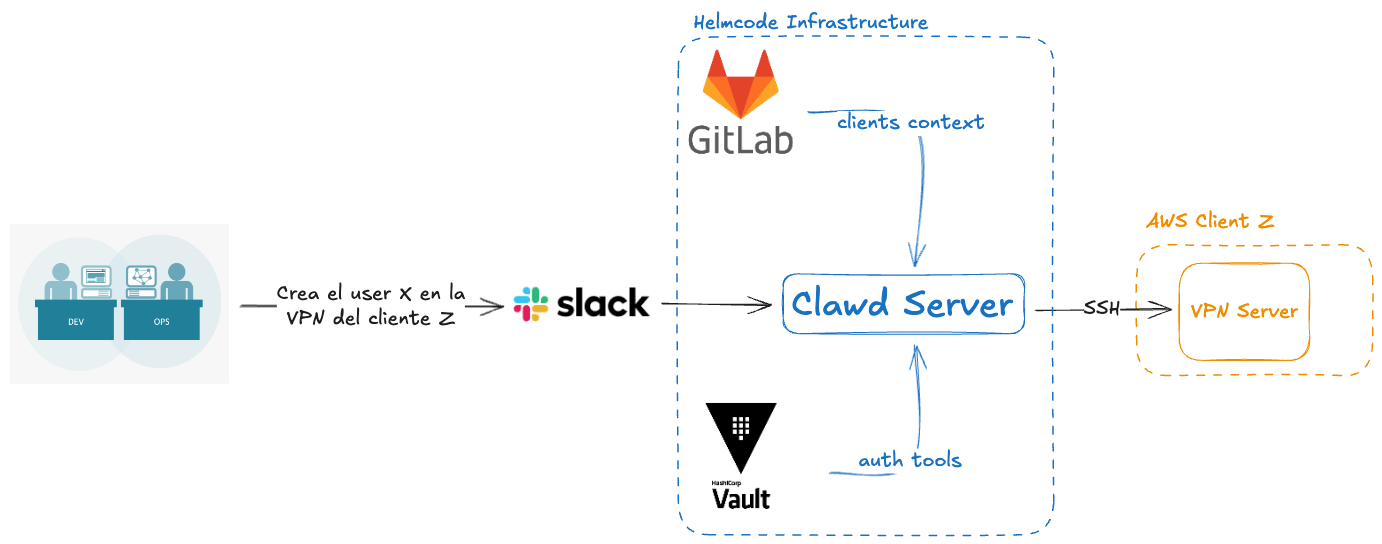
- Solicitarle crear un usuario de VPN en un cliente concreto. El flujo a grandes rasgos para hacer esto era el siguiente:
- El equipo a través de Slack le pide la acción.
- Clawd revisa el contexto del cliente solicitado para saber cómo debe proceder y cómo debe autenticar con la herramienta que necesita.
- Usa Vault para Autenticar.
- Ejecuta la acción.
- Contesta por Slack cuando ha finalizado.
- Solicitarle el borrado de varios discos (PVC de Kubernetes) que no tenían uso y se habían quedado huérfanos:
- El flujo principal es similar al anterior con una gran variación.
- Ahora además de eso, gracias a que en su memoria principal le hemos dado indicaciones de cómo usar la API de nuestro gestor de tareas, no solo realizó lo que se le solicitó sino que registró su propia tarea.

- Finalmente, el flujo más complejo que hemos conseguido hasta el momento y que ya empieza a vislumbrar la posibilidad de tener un compañero de IA trabajando codo con codo con nosotros es el siguiente:
- El flujo principal de contexto y auth sigue siendo igual que el primer ejemplo que vimos.
- Sin embargo aquí hemos añadido:
- La posibilidad de que Clawd detecte cuándo le asignamos un ticket en nuestro gestor de tareas. Esto es gracias a un script que hace polling de la API del gestor de tareas y cuando detecta una tarea nueva asignada a Clawd, envía un mensaje a Clawd para que se active.
- Cuando detecta un nuevo ticket, analiza qué le estamos solicitando y para qué cliente para saber según esto el contexto y las herramientas que necesita.
- Después, cuando él mismo se ha creado un plan de acción nos solicita autorización a través de un grupo de Slack para poder llevar a cabo su tarea:
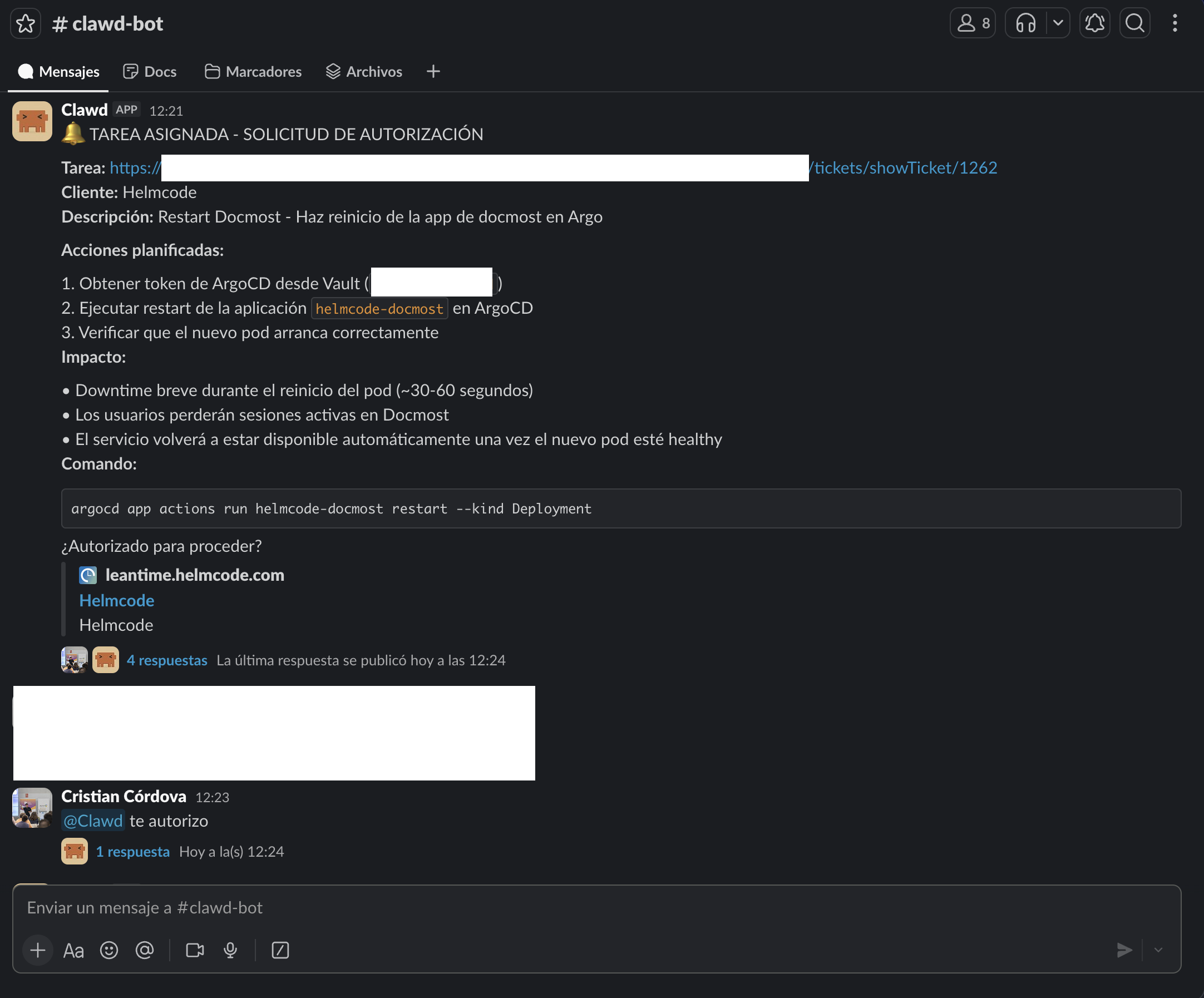
Finalmente y SOLO tras darle autorización, ejecuta su plan de acción y nos reporta el estado de lo que ha realizado. Cuando ya cree que está lista su tarea, en nuestro gestor de tareas deja el ticket en el estado de "Testing" y nos avisa:
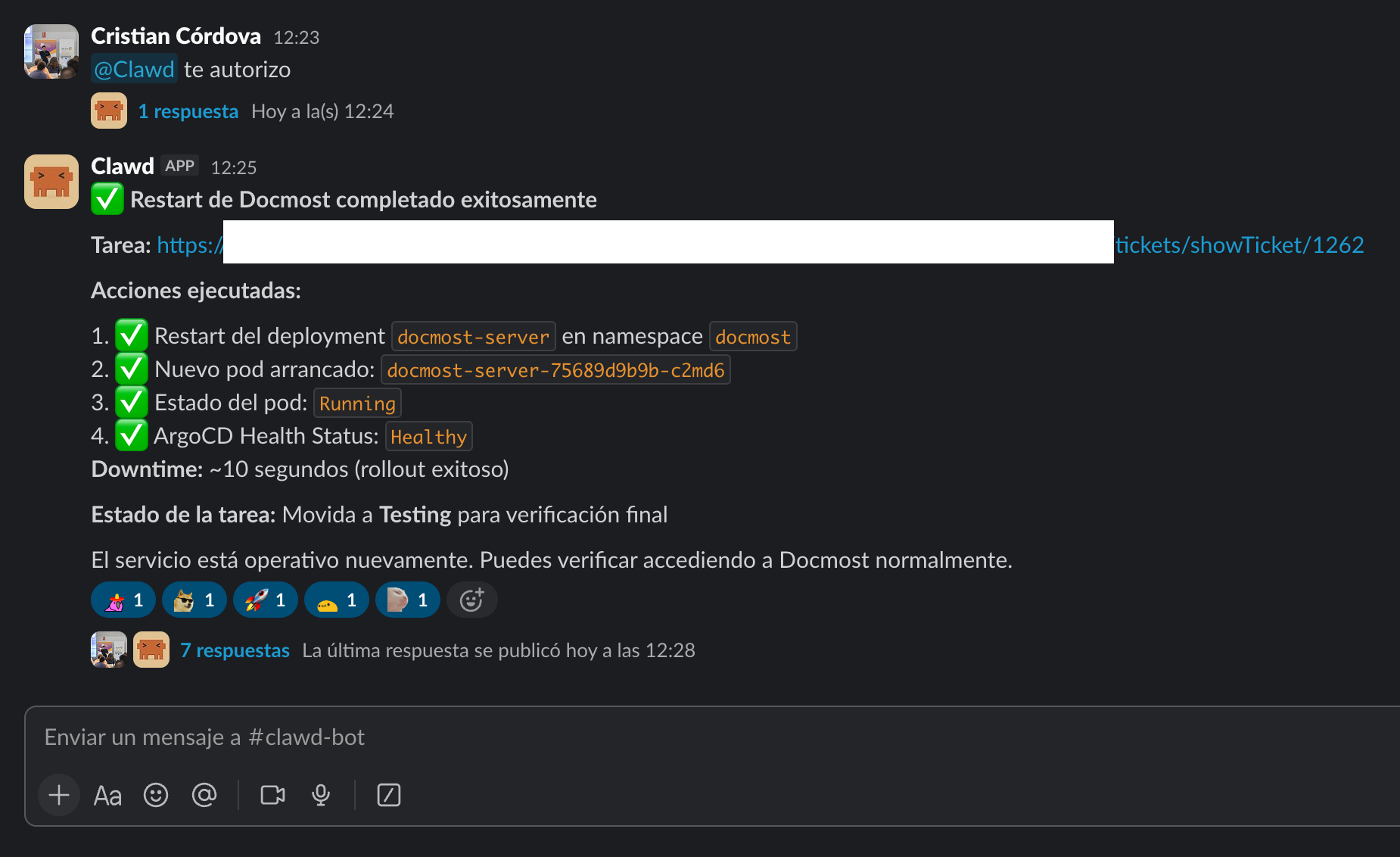
De esta forma, alguien del equipo de infraestructura (humano) puede validar que lo que Clawd ha realizado es correcto. Si es así, cierra el ticket.
Este flujo ya no solo requiere procesamiento por parte del agente sino que pausa su procesamiento a la espera de autorización explícita del equipo y registra todo su trabajo en nuestro gestor de tareas, igual que si fuésemos uno de nosotros haciendo sus tareas del día a día.
Algunos aprendizajes
Si bien el agente es una maravilla y hace cosas increíbles. Requiere mucho contexto y documentación adecuada para que sepa exactamente qué hacer y cómo debe hacerlo. Si dejas que algo quede al azar estas, literalmente, tirando una moneda al aire y puedes tener pruebas exitosas como las anteriores o también pruebas infructuosas como esta que nos ocurrió:

Clawd hizo su primera cagada, no le sincronizaba una App en ArgoCD y no se le ocurrió otra idea que eliminar la App. Afortunadamente, lo hizo sin prune, es decir. Como el mismo indica no se cargó realmente mas que el recurso de Argo que luego además lo recreó y sacó la tarea adelante pero el susto ya nos lo llevamos.
Por seguridad, obviamente, estamos probando con aplicaciones y entornos que son completamente seguros y que si se rompen, eliminan u ocurre algo fuera de lo esperado, es fácilmente recuperable y por eso nos reímos. Sin embargo, nos deja una lección muy clara de que esto corriendo sin control, sin contexto y sin instrucciones claras, es francamente peligroso y debemos tener mucho cuidado.
Reflexión final
Esto es una opinión muy subjetiva de quien escribe este post (Cristian Córdova).
La industria está cambiando a marchas muy aceleradas. El tiempo en que la IA hacia autocompletados mas o menos buenos en el código parece que ha sido hace un siglo y apenas ha pasado ~1 año y pico.
Estamos en un punto donde ya podemos decir que el 99% del código escrito puede ser perfectamente generado por algún modelo de IA. Y ya no solo eso, sino que ahora gracias a los Agentes y a los MCP, ya no solo generan cosas sino que tienen también la capacidad de operar como el caso de Clawd.
Como hemos podido ver no son 100% autónomos, requieren aún una gran cantidad de documentación, guía, validaciones y un sin fin de contexto para poder hacer lo que realmente queremos que hagan. Por fortuna los modelos irán mejorando y la tecnología irá avanzando y esto cada día será mucho más sencillo que el anterior.
A mi no me gusta dar predicciones de nada por lo que no sé si perderemos nuestro trabajo o seremos más necesarios que nunca o a saber qué ocurre pero lo que si tengo claro es que no hago mi trabajo igual que lo hacía hace 5 años. Es más, ni siquiera a como lo hacía hace unos pocos meses. Así que lo importante es aprender para estar listos para todo lo que pueda venir.
Yo, al menos, estoy sumamente emocionado con todo esto.
En Twitter, estoy contando todos los días las diferentes pruebas que estamos haciendo, tanto las buenas como las malas. Estaré encantado de escuchar vuestro feedback o ideas sobre todo esto. ¡Hasta la próxima! 🖖